|
Recovered Cameras
|
Self-Captured Data

|

|

|

|

|

|

|
Abstract
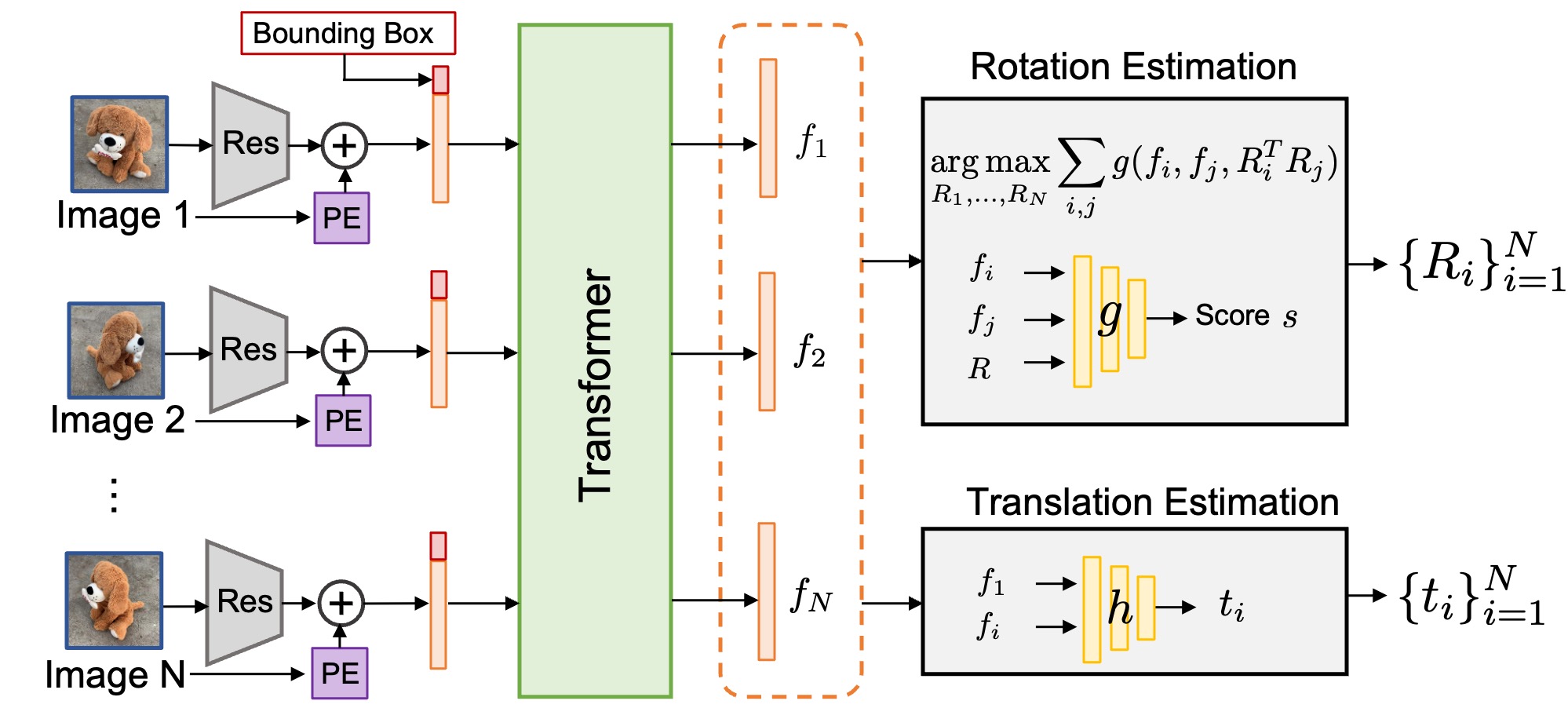
We address the task of estimating 6D camera poses from sparse-view image sets (2-8 images). This task is a vital pre-processing stage for nearly all contemporary (neural) reconstruction algorithms but remains challenging given sparse views, especially for objects with visual symmetries and texture-less surfaces. We build on the recent RelPose framework which learns a network that infers distributions over relative rotations over image pairs. We extend this approach in two key ways; first, we use attentional transformer layers to process multiple images jointly, since additional views of an object may resolve ambiguous symmetries in any given image pair (such as the handle of a mug that becomes visible in a third view). Second, we augment this network to also report camera translations by defining an appropriate coordinate system that decouples the ambiguity in rotation estimation from translation prediction. Our final system results in large improvements in 6D pose prediction over prior art on both seen and unseen object categories and also enables pose estimation and 3D reconstruction for in-the-wild objects.
Paper

RelPose++: Recovering 6D Poses from Sparse-view Observations
Amy Lin*, Jason Y. Zhang*, Deva Ramanan, and Shubham Tulsiani
@inproceedings{lin2024relposepp,
title={RelPose++: Recovering 6D Poses from Sparse-view Observations},
author={Lin, Amy and Zhang, Jason Y and Ramanan, Deva and Tulsiani, Shubham},
booktitle={2024 International Conference on 3D Vision (3DV)},
year={2024},
}Video
Downstream 3D Reconstruction

Code
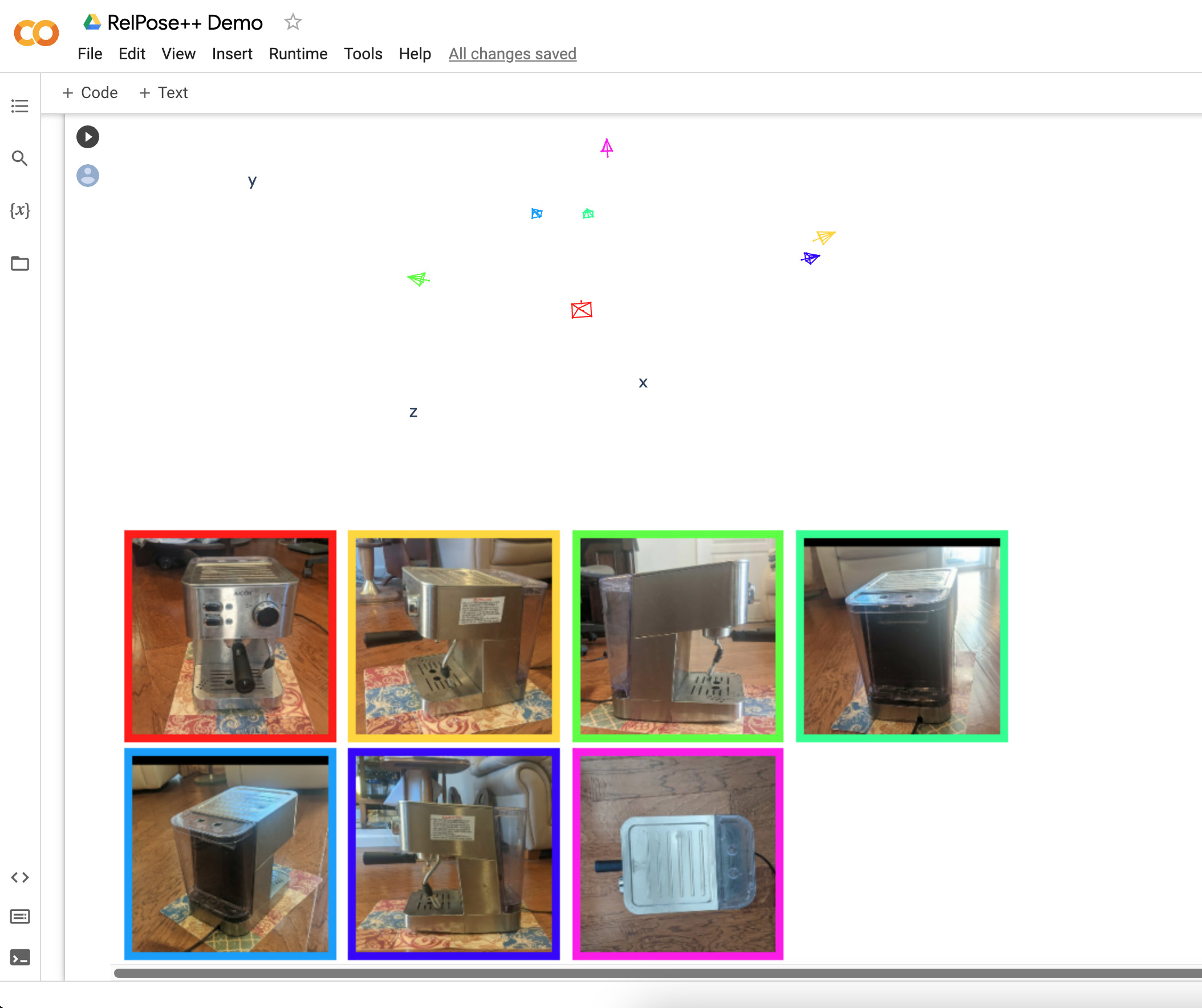
CO3D Results

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
Acknowledgements
This work was supported in part by the NSF GFRP (Grant No. DGE1745016), a CISCO gift award, and the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/Interior Business Center (DOI/IBC) contract number 140D0423C0074. Webpage Template.